We get used to the old cliché, “content is king,” yet this has been overruled by a more nuanced reality: the new king, accessibility. Words alone are no proof. According to Wyzowl State of Video Marketing 2025, video consumption accounts for over 82% of all internet traffic, which is shocking. With that being said, the bottleneck for creators and enterprises is no longer production: it is localization.
For decades, the choice for global distribution was a binary one: affordable but distracting subtitles, or high-quality but prohibitively expensive studio dubbing. However, the rise of neural networks and generative AI has introduced a third path. Today, automated video translation and dubbing are not just “good enough”—they are becoming the industry standard. This guide provides a deep-dive technical walkthrough on how this architecture works and how you can implement it using professional tools.
The Global Video Shift: Why Dubbing Matters Now
Historically, dubbing was reserved for high-budget cinema. Wikipedia notes that in the early 1930s, countries like France, Italy, and Spain established strict dubbing cultures to preserve linguistic identity—a process that required months and thousands of dollars per hour of footage.
Fast forward to today, and the “MrBeast effect” has changed everything. By leveraging YouTube’s Multi-Language Audio (MLA) feature, creators have seen an average of 25% increase in watch time from non-primary language viewers. According to data shared on LinkedIn by video marketing leads, localized audio doesn’t just increase reach; it improves brand trust by 91%, as viewers engage more deeply with content delivered in their native tongue.
How AI Video Dubbing Works
To understand how to automate this process, one must look “under the hood” at the three-pillar architecture that defines modern AI dubbing.
Pillar I: Automatic Speech Recognition (ASR)
The first step is converting audio waveforms into structured text. In 2026, models like OpenAI’s Whisper and Google’s latest Gemini-integrated ASR have reached “human-parity” accuracy. Technically, ASR involves:
- Feature Extraction: Converting audio into a spectrogram.
- Neural Mapping: Predicting sequences of characters or “tokens” based on acoustic patterns.
- Timestamping: Precisely mapping every word to a millisecond on the timeline, which is crucial for the later synchronization phase.
Pillar II: Neural Machine Translation (NMT)
A quick reminder, once the text is extracted, it must be translated. And simple word-for-word translation fails to cater to audiences needs because of Sentence Expansion. I will give you something to chew on: for the same meaning, a sentence in English is often 20% shorter than in German. Modern NMT systems, which use Context-Aware LLMs (Large Language Models), can guarantee that the text they create is not only well-translated but also fits the original timing.
Pillar III: Text-to-Speech (TTS) & Voice Cloning
The final pillar is the synthesis of the new audio.
- Prosody & Timbre: AI now captures the “rhythm” (prosody) and “color” (timbre) of the human voice.
- Voice Cloning: This involves training a neural model on a 30-second sample of the original speaker’s voice to generate a digital twin that can “speak” any language while retaining the original’s personality.
Technical Challenges in AI Video Translation: Solving the Timing Expansion Problem
A common question on Quora among developers is: “How do I handle the extra length of translated audio?” In a technical walkthrough, this is known as Time Alignment. If the translated audio is longer than the original scene, the system must choose between:
- Time-Stretching: Speeding up the voice (which can sound unnatural).
- Script Contraction: Using AI to summarize the translation so it fits the window without losing meaning.
- Visual Padding: Slowing down the video to match the longer audio.
How to Automate Video Dubbing with VMEG AI
While you may create a custom pipeline with Python and various APIs, most professional teams rely on an integrated platform to do the heavy lifting. VMEG AI has emerged as a market leader in this field by merging these technological foundations into a browser-based application.
What is VMEG AI?
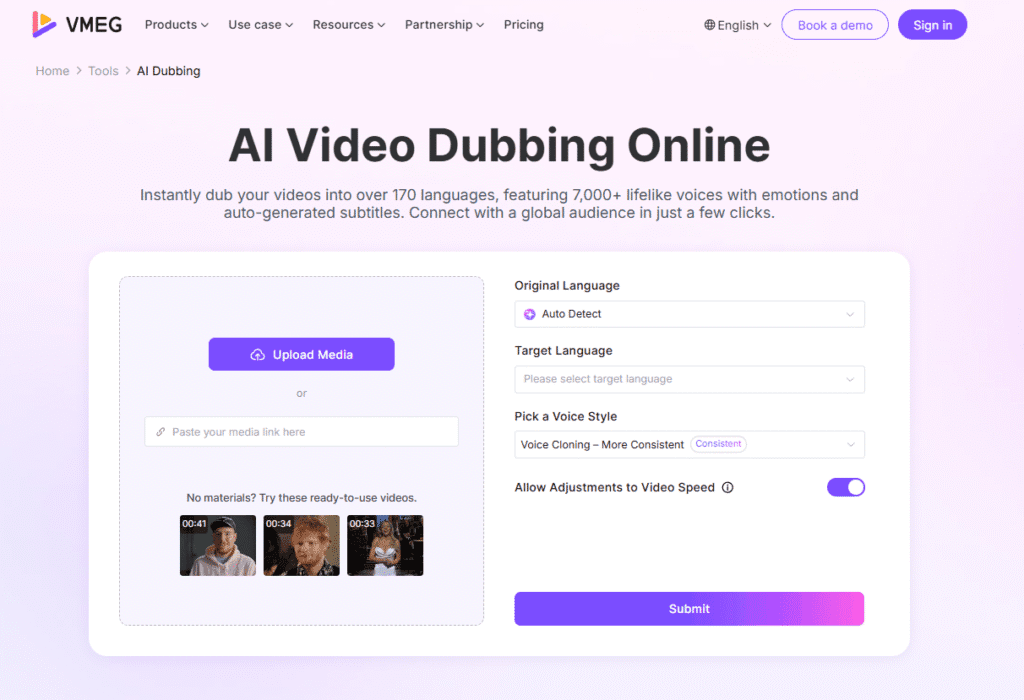
VMEG AI is a comprehensive video localization platform that automates transcription, translation, and dubbing of video content. It is designed to reduce the “robotic” quality of standard AI voices and includes a library of over 7,000 voices with emotive intonation.
- Multi-Speaker Detection: The AI automatically identifies different people in a video and assigns a unique, consistent voice clone to each.
- AI Lip-Sync: This is the “holy grail” of dubbing. VMEG’s engine uses phoneme-level mapping to subtly adjust the person’s mouth movements in the video to match the new language’s sounds.
- Context-Aware Editing: A built-in “Studio” allows you to tweak the translation before the final audio is generated, ensuring that industry-specific jargon is handled correctly.
Step-by-Step Tutorial: Dubbing Your First Video
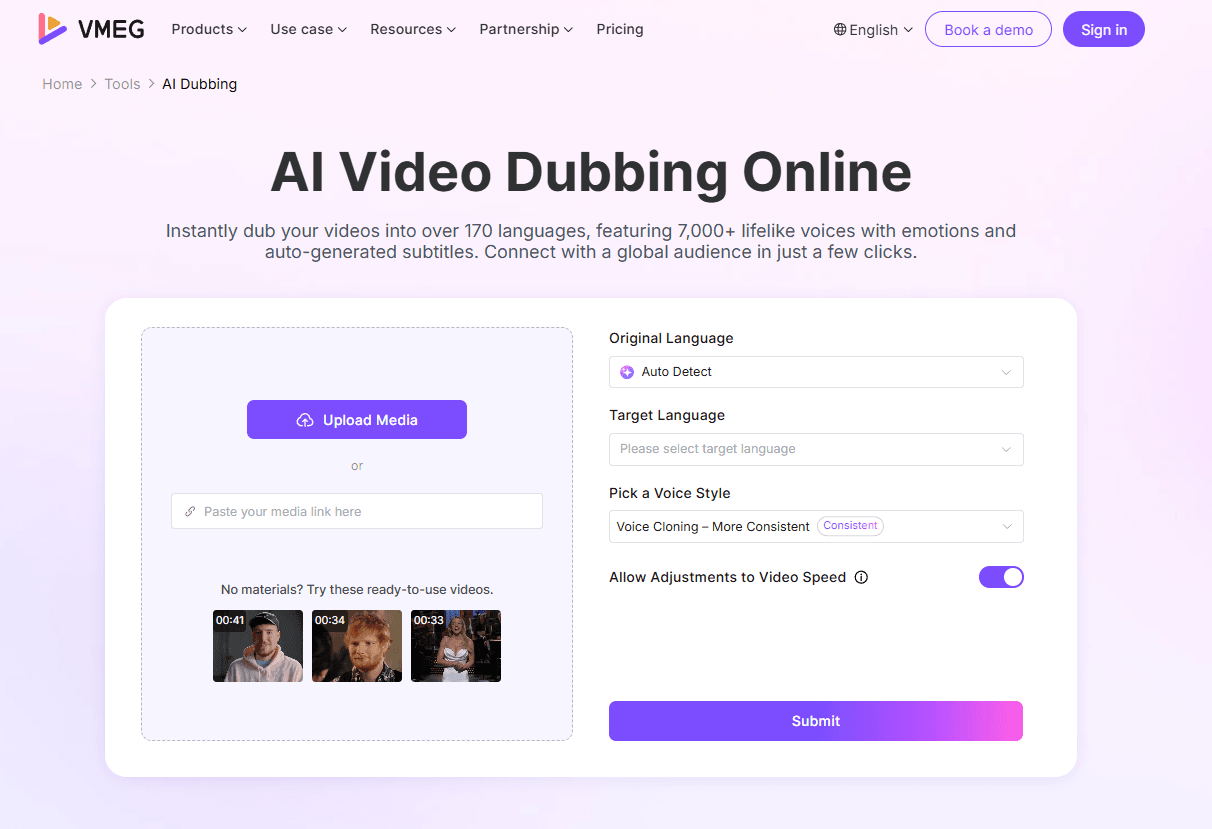
Step 1: Resource Upload
In order to make magic happen, first, upload your source file (MP4, MOV, etc.) or simply paste a link from YouTube or Google Drive. VMEG’s cloud infrastructure easily handles files with a resolution of no more than 4 K and 2GB in size.
Step 2: Language & Voice Configuration
Select your target language from more than 170 options after choosing your source language (or using “Auto-Detect”). You have the option to use voice cloning at this point. The algorithm analyzes the tone of the original speaker to produce a localized version that nevertheless sounds like “you.”
Step 3: Transcription Review & Translation
In this system, you will find a side-by-side view available. On the left, you will find the original transcript, and there is the AI translation on your right.
Tip: Check for “Expansion.” If the German text looks twice as long as the English, use the “AI Refine” tool to shorten the sentence length while keeping the core message.
Step 4: AI Lip-Sync & Audio Generation
Click “Generate Dub.” This triggers neural synthesis. If you hit Lip-Sync, the platform will perform a post-processing pass where it modifies the video’s pixels, basically areas around the mouth, to align with the new audio, with little error.
Step 5: Quality Assurance & Export
View the video in the browser. You can change the “Speed” and “Volume” of individual segments. Once you’re pleased, export the video. VMEG enables a 17x faster turnaround than standard approaches, allowing a 10-minute movie to be localized in under 15 minutes.
Strategic Best Practices for Global Reach
To optimize the impact of automated dubbing, consider the following main strategies:
Manage Your Technical Glossary
Industry jargon like Machine Learning, SaaS, and API should often be written in English or follow brand rules. Many professional systems allow you to lock down specific terms to avoid erroneous or confusing translations.
Optimize for Global Discoverability
Localizing audio alone isn’t enough—you should also adapt supporting metadata to improve visibility and engagement.
- Subtitles/CC: Always provide an SRT file. Many viewers watch videos on mute, especially on mobile devices.
- Thumbnails: Use localized text in thumbnails. Audiences are more likely to click visuals that use their native language.
Adopt a Human-in-the-Loop (HITL) Workflow
As highlighted in RWS’s 2026 Guide to AI Dubbing, the most effective workflows combine AI efficiency with human oversight:
- AI performs roughly 90% of the work (transcription and translation).
- Native speakers review the output to ensure cultural nuance and tone are accurate.
FAQ: Automated Video Translation and AI Dubbing
What is automated video translation?
It is the practice of using artificial intelligence to transcribe spoken input into another language, primarily through video. The workflow involves three key steps: speech recognition (ASR), translation (NMT), and voice synthesis (TTS). Instead of transcribing and recording voice-overs by hand, AI systems can perform these tasks quickly and efficiently, saving you both time and money.
But how accurate is AI video dubbing today?
Modern AI dubbing systems have advanced significantly in recent years. For clear audio recordings, advanced models trained on extensive speech and language datasets can achieve a level of transcription accuracy comparable to that of humans. Context-aware language models understand phrase structure and tone, improving translation quality.
However, many businesses still use a Human-in-the-Loop (HITL) strategy, where native speakers verify AI-generated translations to ensure that cultural nuances and industry-specific terminology are correct.
Can AI replicate the original speaker’s voice?
Yes. Many AI dubbing platforms now support voice cloning technology, which creates a digital replica of a speaker’s voice. By analysing a short audio sample — sometimes as little as 30 seconds — the system can generate speech in other languages while maintaining the original speaker’s tone, pace, and personality. This capability enables content creators to maintain a consistent brand voice across multiple languages.
How long does it take to translate and dub a video with AI?
Traditional dubbing studios may take days or even weeks to localise a video. In contrast, AI-powered platforms can complete the process much faster. For instance, modern video localisation tools can often translate and dub a 10-minute video in under 15 minutes, depending on the complexity of the audio and the number of languages selected.
What are the biggest challenges in AI video dubbing?
One of the most common technical challenges is the “expansion problem.” When translating from one language to another, sentences can become longer or shorter, which affects synchronization with the video.
To solve this, AI systems may use techniques such as:
- Time-stretching the generated audio
- Script contraction to shorten translated sentences
- Video timing adjustments to match longer speech segments
These processes help maintain natural timing between the visuals and the new audio.
Conclusion
Automating video translation and dubbing is no longer a dream far from reach; it is a tactical imperative for anyone trying to grow their force in the digital age. Understanding the technological foundations of ASR, NMT, and TTS, as well as employing powerful tools like VMEG AI, may help you transform your content from a local asset to a worldwide powerhouse.